Forum Replies Created
-
AuthorPosts
-
 MajklParticipant
MajklParticipantFor the record, how I turned out:
The command “nxserver –updatedb” did not help.
After a complete uninstall, deleting everything from NX and a new installation of ED 8.3.1, it works OK.
So I agree there was some issue with the NXv7 to NXv8 transition, we ended up with a clean reinstall of all EDs (and similarly had to clean reinstall the Enterprise Clients, due to disk sharing issues).
MajklParticipantWhat previous version was the upgrade from?
We have about 30 users. Most users had a problem with disk mapping after upgrading the client from NXv6/7 to NXv8 (32-bit), uninstalling NMv8 32-bit and installing NMv8 64-bit, but the disk was still not mapped. We are using NoMachine Enterprise Client on Windows 10.
For all of them, the problem was solved by uninstalling the client, rebooting, finding all occurrences of NX files (especially .nx directories in the profile or parts of the old installation that might have been under the user’s profile) and manually deleting them, rebooting, a new installation of NX client 8.2.3 – and the drives started connecting again.
The problem on the client side, the server side could be different (and in the debug log of the server it appeared that the disk for sharing was offered to the client, but it did not appear in the menu in the client). But it could be that we normally manage the install/uninstall/upgrade centrally with ZenWorks and it appeared that there was a remnant of the previous version somewhere that caused the conflict.
We still have some disk issue on the client side, but that probably only applies to the published application mode (Terminal server edition) and not the whole desktop sharing.
(Britgil: Please, did you get the debug log emailed about the falling ED?)
MajklParticipantNM7 ED: OK
NM8 ED 32bit and 64bit – they fall
Now we have the last ED that hasn’t been reinstalled from scratch and I see that it’s just dead. 🙂
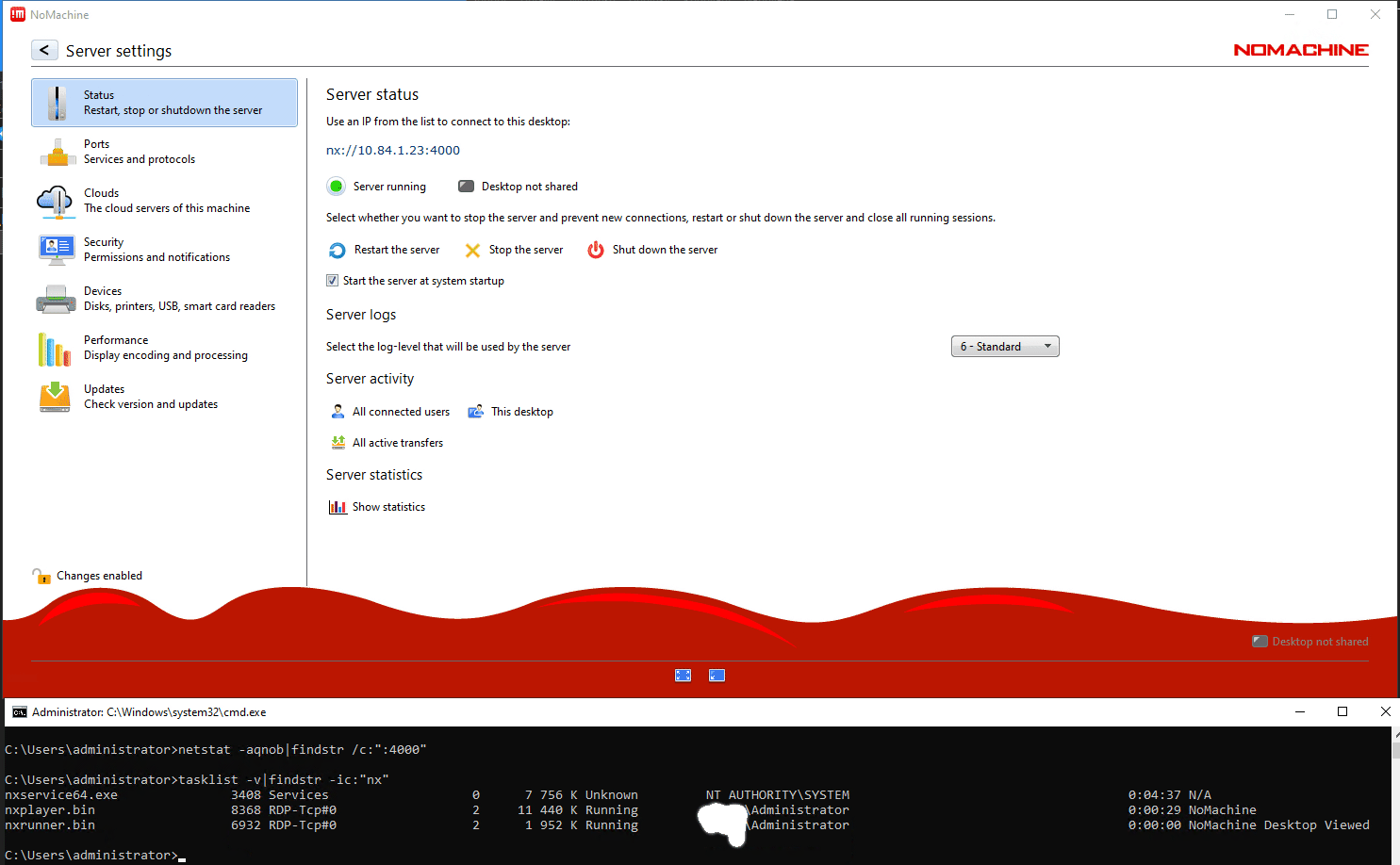
See Annex. NM service panel reports that it is running. But according to netstat and tasklist, it can be seen that the nxd service is missing (and a few others, if I compare with a working node) and nothing is listening on the TCP/4000 port. If I switch to the ports panel: NX, SSH, HTTP start as running first, and after a few seconds it correctly shows that nothing is running (only NX is enabled).
So reboot, turn on debug and wait for the crash… This ED is now free for experimentation. Otherwise, it is connected to a cloud server (direct, tunnel mode).
Attachments:
MajklParticipantI see this topic has come up a few times here. We have a very similar experience. In our case, NoMachine Enterprise Desktop with Windows 10.
After restarting, although the service is enabled, it cannot be connected (must be restarted manually via RDP connection). Or after some time, in the order of minutes to about 3 days after the restart, the service will cease to be available. Or I’m connected and the desktop suddenly freezes. If I’m quick about opening a new connection, I continue on the new one (and the old one shows a frozen state until I close it). If I don’t connect in a while, the server freezes as well.
Freezing desktops in all cases have a longer history, have undergone NMv7 upgrade to NMv8 (32 bit), uninstall and install NMv8 64-bit. Another thing is that it’s about loaded systems. For example, it is enough to disable the Windows search service or move the system to a more powerful/less loaded cluster node and the problems will stop (all these are virtualized libvirtd/KVM systems, RedHat cluster suite, CentOS7, Fujitsu Primergy servers in the background, multiple clusters). With NMv7 there were no such problems, even systems that are cleanly installed directly as NMv8 64-bit are OK.
-
AuthorPosts